
Last und Performance Tests: Grundlagen
Fast jeder hat schon etwas von Last und Performance Tests gehört, aber nicht jedem ist klar, was wirklich dahinter steckt.
In diesem Artikel erklären wir die Grundlagen und die unterschiedlichen Begrifflichkeiten, zeigen die unterschiedlichen Testarten und die dahinter stehenden Konzepte.
Was sind Last und Performance Tests?
Dabei handelt es sich um nicht-funktionale Softwaretests, die mit Hilfe von diversen Werkzeugen eine hohe, möglichst realistische Last auf der zu testenden System-Infrastruktur erzeugen.
Was soll durch Last und Performance Tests aufgedeckt werden?
1. Latente, funktionale Fehler. Das sind die Fehler, die in den funktionalen Tests nicht in Erscheinung treten z.B. fehlerhafte Pfade im Programm, die erst bei höherer Last betreten werden.
2. Noch nicht entdeckte funktionalen Fehler, weil z.B. nicht alle Grenzbereiche getestet wurden.
3. Eventuelle Schwächen im Datenmodell: große Tabellen, nicht ausbalancierte Indizies oder gar keine Indizies, ungünstige Tabellen Joins usw.
4. Eventuelle Schwächen in der Architektur, z.B. Deadlocks, zu große Transaktionen im Code.
5. Nachweis über die Erfüllung von SLA’s, hier liegt der Fokus auf Performance Tests mit definierter Grundlast und definierter Anzahl der zu testenden Transaktionen, um die Antwortzeiten einzelner Transaktionen zu messen und gegen Service Level Agreements (SLA’s) zu prüfen.
6. Nachweis über die Erfüllung von nicht-funktionalen Requirements (NFR’s) mit dem Fokus auf Last Test der gesamten Prozesskette unter unterschiedlichen Bedingungen.
7. Stabilität und Zuverlässigkeit der Anwendung unter lang andauernder Last mit wechselnden Spitzen.
8. Skalierbarkeit der Anwendung, Effizienz und Ressourcen Verbrauch
Testarten und deren Fokus?
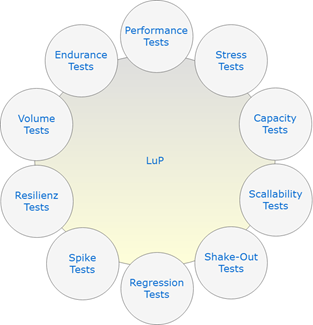
1.Performance Test
Bei Performance Tests wird die Last während des Tests bis zu definierter Last schrittweise erhöht, indem immer mehr virtuelle Benutzer aktiviert und mit Aufgaben versehen werden. Nach der Ramp-Up Phase sollten die folgenden Parameter während des Tests überwacht und in verschiedenen Testphasen verglichen werden:
- Antwortzeiten der Anwendung
- Anzahl der pro Sekunde verarbeiteten Anforderungen oder anwendungsspezifischen Transaktionen
- Check gegen die SLAs und Baseline (Referenzlauf)
- Prozentsatz fehlgeschlagener Anforderungen (Fehlerrate)
2. Stress Test
Jedes System hat eine Kapazitätsgrenze. Wenn die auf das System erzeugte Last darüber hinausgeht, reagiert die Anwendung sehr langsam und kann unter Umständen Fehler erzeugen.
Primäre Aufgabe von Stresstests ist es also diese Grenzen zu finden und zu prüfen, ob
- das System beim Erreichen dieser Grenzen mit der Belastung richtig umgehen kann (kein Absturz, Richtige Meldungen über die Überlastung)
- das Verhalten nach der Last den Erwartungen entspricht
- das System in der Lage ist mit gewünschten Leistungsmerkmalen zum normalen Betrieb zurückzukehren
3. Capacity Test
Capacity Tests werden durchgeführt, um herauszufinden, wie viele Benutzer gleichzeitig mit der Anwendung arbeiten können, ohne die Qualität zu beeinträchtigen. Virtuelle Benutzer werden während des Tests nach und nach hinzugefügt. Hier sind die Qualitätskriterien im Voraus bekannt. Es wird geprüft, ob diese eingehalten werden.
4. Scalability Test
Scalability Tests überprüfen die Fähigkeit des Systems erweitert zu werden, um die geforderte Anforderung erfüllen zu können. Das Testen der Skalierbarkeit ist eine nichtfunktionale Testmethode, bei der die Leistung einer Anwendung anhand ihrer Fähigkeit gemessen wird, die Anzahl der Benutzeranforderungen oder anderer Leistungs-Attribute zu vergrößern oder zu verkleinern. Skalierbarkeitstests können auf Hardware-, Software- oder Datenbankebene durchgeführt werden. Die für diesen Test verwendeten Parameter sind anwendungsspezifisch unterschiedlich. Es kann sich dabei um die Anzahl der Benutzer, die CPU-Auslastung und die Netzwerkauslastung oder aber um die Anzahl der verarbeiteten Anforderungen handeln.
5. Shake-Out Tests
Der Shake-Out Test ist eigentlich kein Leistungstest, sondern dient lediglich als vorbereitende Maßnahme für die durchzuführenden Tests. Der Test soll sicherstellen, dass die Skripte in der Testumgebung funktionsfähig sind, die für die Erfassung von Metriken konfigurierten Leistungsmonitore wie erwartet funktionieren. Man kann auch, mit wenigen virtuellen Usern (VU’s), Zeiten messen, um festzustellen, wie lange es dauert, um die Transaktionen abzuschließen und damit in der Lage zu sein die Laufzeiten der Tests zu berechnen.
6. Regression Test
In der Praxis steht der Begriff des Regressionstests für die reine Wiederholung von Testfällen für bereits getesteten Objekte nach einer Modifikation der der Testobjekte. Es soll sicherstellen, dass die Änderungen keine fehlerhaften Zustände eingebaut haben. Die Testfälle selbst müssen spezifiziert und mit einem Soll-Ergebnis versehen sein, welches mit dem Ist-Ergebnis eines Testfalls verglichen wird. Ein direkter Bezug auf die Ergebnisse eines vorherigen Testdurchlaufs findet nicht statt.
7. Spike Test
Spike-Tests werden als eine Art von Leistungstests definiert, bei denen die Anwendung mit extremen Zu- und Abnahmen der Last, wie Anzahl der Benutzer oder zu verarbeitende Datenmenge getestet wird, um die Fähigkeit des Systems sich von diesen Lastspitzen zu erholen und in den stabilen Zustand zurückzukommen zu prüfen.
8. Resilienz Test
Die Ausfallsicherheit von Softwarelösungen bezieht sich auf die Fähigkeit einer Lösung, die Auswirkung eines Problems auf einen oder mehrere Teile eines Systems zu absorbieren und gleichzeitig dem Unternehmen ein akzeptables Serviceniveau bereitzustellen.
9. Volume Test
Der Volume Test ist eine spezielle Art nicht funktionaler Tests. Ziel von Volumen Tests ist es, das Verhalten des Systems zu testen, wobei die Last auf das zu testende System mittels erheblicher Datenmengen erzeugt wird z.B. durch Down/Upload von sehr großen Daten. Die Komplexität jeder Transaktion sollte maximiert werden z.B. durch Benutzung von komplexen Schlüsselwörtern bei Suchanfragen, um sehr lange Ergebnisliste zu erhalten.
10. Endurance Test
Endurance (Ausdauer) Tests, die auch als „soak testing“ bezeichnet werden, sind Tests, die verwendet werden, um zu überprüfen, ob das System die Last für eine lange Zeit oder eine große Anzahl von Transaktionen aushält. In der Regel werden verschiedene Arten von Problemen bei der Ressourcenzuweisung aufgezeigt. Beispielsweise wird ein kleiner Speicherverlust bei einem Schnelltest selbst bei hoher Last nicht erkannt. Es wird empfohlen eine sich ändernde periodische Belastung für eine lange Testdauer zu verwenden.
Was wird benötigt?
1. Infrastruktur
Als erstes ist es notwendig eine produktionsnahe, adäquate Test-Umgebung zu haben, worauf die Anwendung deployed und getestet werden kann. Die externen Schnittstellen können simuliert werden.
2. Anwendung
Die Anwendung muss funktional getestet, deployable und weitestgehend fehlerfrei sein.
3. Exklusivität
Idealerweise sollte man ein exklusives System haben, damit die Tests nicht durch andere Aktivitäten beeinflusst oder anderen Tests durch die eigenen Aktivitäten gestört werden. Es macht besonders dann Sinn, wenn man gemeinsame Datenquellen nutzt, die nach den Tests wiederhergestellt oder zurückgerollt werden müssen.
4. Testdaten
Fast alle Tests konsumieren Testdaten. Die Gestaltung der Testdaten kann nicht nur die Stabilität der Skripte, sondern auch das Verhalten des Systems während der Tests beeinflussen. Die Testdaten sollten auf der einen Seite ähnlich sein, um ähnliche Ergebnisse zu liefern und auf der anderen Seite müssen sie soweit es geht die unterschiedlichen Permutationen abdecken, um z.B. Caching-Effekte auszuschließen. Daten können während der Tests “verbrannt” werden (ein abgeschlossener Vertrag kann bei der nächsten Ausführung nicht erneut abgeschlossen werden). Die Testdaten können aus den vorhandenen Daten selektiert, während der Tests oder vor dem Test in einem Batchlauf angelegt werden.
Die Daten für Neuanlage können einmalig in z.B. CSV Dateien oder vor der Ausführung durch einen Generator angelegt werden.
5. Wiederholbarkeit
Ein Test sollte nach Möglichkeit wiederholbar und die Ergebnisse vergleichbar sein. Dafür ist es notwendig vor dem Test immer die gleiche Ausgangssituation herbeizuführen. Dazu gehören z.B. gleiche Daten und Datenmengen, gelehrte Caches, neu gestartete Dienste oder neu gestartetes System. Ein Test, was immer z.B. einen Kunden-Datensatz anlegt, kann in den meisten Fällen nur einmal ausgeführt werden, da hier in der Regel unterschiedliche Constraints verletzt werden. Erleichterung der Wiederholbarkeit bietet z.B. Oracle’s Flashback Recovery, System Backup und Recovery, Einsatz von Virtuellen Images usw.
6. Skripte
Keine Skripte – kein Test. Hier kann man jedoch zwischen eigens erstellten oder generierten Skripten unterscheiden. Die sehr einfachen Skripte, z.B. “Page-Hopping”, könnten, abhängig von dem eingesetzten Tool, deklarativ zur Laufzeit generiert werden. Die meisten jedoch müssen manuell erstellt oder aufgezeichnet und auf die Lauffähigkeit geprüft werden. Häufig müssen die Skripte modifiziert werden, wie z.B. Entfernen unnötiger Schritte, Instrumentierung, Parametrisierung, Datenbindung, Extraktion, Substitution von dynamischen Werten durch variable Werte, Validierung, Definition der Transaktionen usw.
7. Last Treiber
Ein Last Treiber ist ein Tool, das in der Lage ist, eine gewünschte Last so realistisch wie möglich auf das zu testende System auszuüben. Die Auswahl eines geeigneten Werkzeugs ist stark von der Anforderung an den Last-Test, wie z.B. maximale Anzahl der virtuellen Benutzer, eigenen Vorlieben, Betriebsvorgaben oder zur Verfügung stehenden Infrastruktur abhängig. Man kann z.B. kein SaaS Werkzeug für die Tests mit Kundendaten auswählen, wenn die Sicherheit der Daten nicht gewährleistet werden kann oder die Policy einfach bestimmt, dass die Tests generell im Intranet stattfinden müssen. Sehr wichtig für die Wahl des richtigen Werkzeugs ist jedoch die zu testende Anwendung selbst. Wenn die Tests nicht nur REST oder SOAP abtesten müssen, sondern auch über HTTP/s mit Berücksichtigung der asynchronen Requests testen müssen, dann wird die Auswahl etwas schwieriger. Noch enger wird es, wenn die Anforderung auch noch die User Experience wie TTI (Time To Interact) berücksichtigt werden muss.
Ein Last Treiber besteht aus einem Controller und leichtgewichtigen Agenten, wobei die Controller auch als Agent fungieren können. Idealerweise gilt der Controller als zentrale Verwaltungs-, Erstellungs/Debug- und Ausführungsstelle.
Der Controller verteilt die Skripte und Daten auf die Agenten laut Szenarien-Definition, startet den Test, sammelt die Metriken von den Agenten ein und erstellt nach Bedarf Reports.
Der Agent startet die virtuellen User und führt denen zugewiesenen Aufgaben laut Szenarien-Definition durch. Er sammelt die Metriken und stellt sie dem Controller bereit. Die gesamten Metriken werden meistens nach dem Test an den Controller übermittelt. Während der Tests werden meistens nur aggregierte Snapshots für das Live Monitoring an den Controller geliefert.
Es kann natürlich vorkommen, dass nicht alle benötigten Fähigkeiten von dem präferierten Last Treiber abgedeckt werden können. Hier könnte ein hybrider Ansatz verfolgt werden und ein Mix aus Tools für den jeweils spezialisierten Bereich in Erwägung gezogen werden, z.B. Jmeter und Selenium.
8. Monitoring
Während des Lasttests muss die System-under-Test (SUT) Infrastruktur überwacht werden. Es soll das Verhalten und die Nutzung (Utilization) der System-Ressourcen für die gesamte Laufzeit der Tests überwacht werden. Die aufgezeichneten Metriken können zeitlich mit der Testausführung korreliert werden und dienen als zusätzliche Quelle für die Reporterstellung. Die Granularität der Metriken ist abhängig vom eingesetzten Monitor. Hier muss man einen gesunden Mittelweg finden zwischen der Belastung der Infrastruktur durch zusätzliche Prozesse, Netzwerklast und der Granularität.
Als sehr nützlich für die Fehlerverfolgung könnte sich der Einsatz der sogenannten APM Systeme erweisen. Das sind Systeme, die Ressource Utilization, Netzwerkpaket-Fluss, auftretende Fehler aufzeichnen, analysieren und in zeitlicher Korrelation über mehrere Technologieschichten bringen können. Die teuren kommerziellen Systeme wie Dynatrace, Appdynamics oder New Relic können mit ihren Agenten ohne dass die Anwendung instrumentiert ist, bis in die Funktionsebene “hinein drillen”. Andere APM Systeme können das nur mit Hilfe von einer Instrumentierung der Anwendungen leisten.
9. Reporting
Reporting muss meistens leider mehr oder weniger manuell erstellt bzw. erweitert werden. Die Reportgeneratoren können meistens die Ergebnisse für Zeitperioden in Form von Charts, Tabellen und Trends gruppiert nach unterschiedlichsten Kriterien erstellen. Meistens sind diese jedoch nicht “Out of the Box” verwendbar. Da es unterschiedliche Quellen für die Report-relevanten Metriken gibt, wie Monitoring, APM, Logging usw., müssen teilweise auch diese im Report berücksichtigt werden.
Anschließende Bewertung, Erläuterung oder Empfehlung kann zumindest zurzeit nicht maschinell erstellt werden. Der Einsatz von Mashine Learning (ML) könnte hier teilweise eine Hilfestellung anbieten, benötigt jedoch mehr Ressourcen, konsistente Meldungen und große Menge an Trainingsdaten bzw. bei Lazy Learning eine Segmentierung der Meldungen durch die Experten, die diese Meldungen einordnen können. Die in einem Last-Test bereitgestellte Menge an Meldungen ist für deren Normierungs- und Vektorisierungsprozess in real time zu groß, so dass die Analyse viel Zeit benötigt und erst offline erfolgen kann. Das Ergebnis der Analyse und der Vorhersage der Quelle für die aufgetretenen Fehler ist jedoch durch unterschiedliche Fokussierung der Tests besser für funktionale Tests, als für die Last und Performance Tests geeignet.
Quellverweise:
https://www.ibm.com/developerworks/websphere/techjournal/1407_col_nasser/1407_col_nasser.html
Redakteur auf Testautomatisierung.org
Technical Lead bei SimplyTest GmbH, Nürnberg
www.simplytest.de
Softwaretester und Entwickler mit über 30 Jahren Berufserfahrung. Schwerpunkt Last und Performancetests.



Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!